
AWS S3 버킷에서 내보낸 녹음 작업
후 AWS S3 기록 대량 작업 통합 설정되면 Genesys Cloud에 있는 녹음을 대량으로 AWS S3 버킷으로 내보낼 수 있습니다. 이 내보내기는 QM 정책을 통해 자동으로 수행하거나 기록 대량 작업 API를 호출하여 명시적으로 수행할 수 있습니다.
이 문서에서는 AWS S3 버킷으로 내보낸 콘텐츠에 대해 자세히 설명합니다.
AWS S3 버킷 콘텐츠
녹음 파일은 다음 구조의 폴더로 AWS S3 버킷으로 내보내집니다.
s3://{bucket}/{organizationId}/year={year}/{month={month}/day={day}/hour={hourOfDay}/conversation_id={conversationId}/
| 자리 표시자 | 설명 |
|---|---|
| {버킷} | S3 버킷 이름. |
| {조직 ID} | 조직 ID입니다. |
| {년도} | 대화가 시작된 연도. |
| {월} | 대화가 시작된 달(숫자). |
| {day} | 대화가 시작된 날. |
| {hourOfDay} |
대화가 시작된 시간입니다. |
| {대화 ID} |
대화 ID입니다. |
폴더에는 대화 중에 보관된 모든 녹음 파일이 포함되어 있습니다. 각 녹음 파일에는 하나의 녹음이 있으며 파일 이름은 녹음 ID입니다.
각 녹음 파일에는 해당 JSON 메타데이터 파일이 있습니다. JSON 메타데이터 파일 이름에는 "_metadata.json" 접미사가 붙습니다.
메타데이터는 내보낸 녹음을 검색하는 데 사용할 수 있습니다. 자세한 내용은 다음을 참조하십시오. Athena+Glue 예시 (녹음 검색 서비스의 예).
메타데이터 파일은 다음 스키마를 포함하는 JSON 형식입니다.
{
“$schema”: “http://json-schema.org/draft-04/schema#”,
"유형": "객체",
"속성": {
“mediaType”: {
"설명": “미디어 유형(통화, 채팅, 이메일, 메시지, 화면 중 하나)”
"유형": "문자열"
},
“mediaSubtype”: {
"설명": “녹음의 하위 유형(트렁크, 스테이션, 컨설트, 스크린 중 하나)”
"유형": "문자열"
},
“mediaSubject”: {
"설명": “녹음의 주제”
"유형": "문자열"
},
“공급자”: {
"설명": “녹음 제공자 유형(예: Edge)”
"유형": "문자열"
},
“userIds”: {
"설명": “사용자 목록”
"유형": "배열",
“항목”: [
{
"유형": "문자열"
}
]
},
“startTime”: {
"설명": “녹음 시작 시간”
"유형": "문자열"
},
“endTime”: {
"설명": “녹음 종료 시간”
"유형": "문자열"
},
“durationMs”: {
"설명": “녹음 기간”
"유형": "정수"
},
"초기 방향": {
"설명": “대화의 초기 방향(인바운드/아웃바운드)”
"유형": "문자열"
},
"aniNormalized": {
"설명": "아니",
"유형": "문자열"
},
“aniDisplayable”: {
"설명": “표시 가능한 형태의 ANI”
"유형": "문자열"
},
“dnisNormalized”: {
"설명": “DNIS”,
"유형": "문자열"
},
“dnisDisplayable”: {
"설명": “표시 가능한 형태의 DNIS”
"유형": "문자열"
},
“queueIds”: {
"설명": "녹음에 대한 대기열 ID 목록"
"유형": "배열",
“항목”: [
{
"유형": "문자열"
}
]
},
“wrapupCodes”: {
"설명": “대화를 위한 마무리 코드”
"유형": "배열",
“항목”: [
{
"유형": "문자열"
}
]
},
“조직 ID”: {
"설명": “대화를 위한 고유 ID”
"유형": "문자열"
},
“conversationId”: {
"설명": “대화와 관련된 고유 ID”
"유형": "문자열"
},
“conversationStartTime”: {
"설명": “대화 시작 시간”
"유형": "문자열"
},
“conversationEndTime”: {
"설명": “대화 종료 시간”
"유형": "문자열"
},
“recordingId”: {
"설명": "녹음에 대한 고유 ID"
"유형": "문자열"
},
“filePath”: {
"설명": "녹음의 원래 경로"
"유형": "문자열"
},
“fileSize”: {
"설명": “녹음 파일 크기”
"유형": "정수"
},
“messageType”: {
"설명": “메시지가 생성된 메시지 플랫폼 유형(예: SMS, Twitter, Line, Facebook, WhatsApp, 웹 메시징, Open, Instagram)”
"유형": "문자열"
},
“languageIds”: {
"설명": “언어의 식별자”
"유형": "배열",
“항목”: [
{
"유형": "문자열"
}
]
},
“screenInformation”: {
"설명": "화면별 정보에는 화면 ID, X 및 Y 위치, 해상도 정보가 포함됩니다."
“유형”: “객체”
}
},
"필수의": [
“mediaType”,
"공급자",
“startTime”,
“endTime”,
“기간Ms”,
“organizationId”,
“conversationId”,
“conversationStartTime”,
“conversationEndTime”,
“recordingId”,
“filePath”,
“fileSize”
]
}
예를 들어 화면 녹화가 활성화된 통화 대화에는 다음 폴더 콘텐츠가 있을 수 있습니다.
아래 이미지에서 .opus 파일은 오디오 녹음 파일이고 .zip 파일에는 화면 녹음 파일이 포함되어 있으며 .json 파일은 각 미디어 파일과 연결된 JSON 메타데이터입니다.
이미지를 클릭하면 확대됩니다.
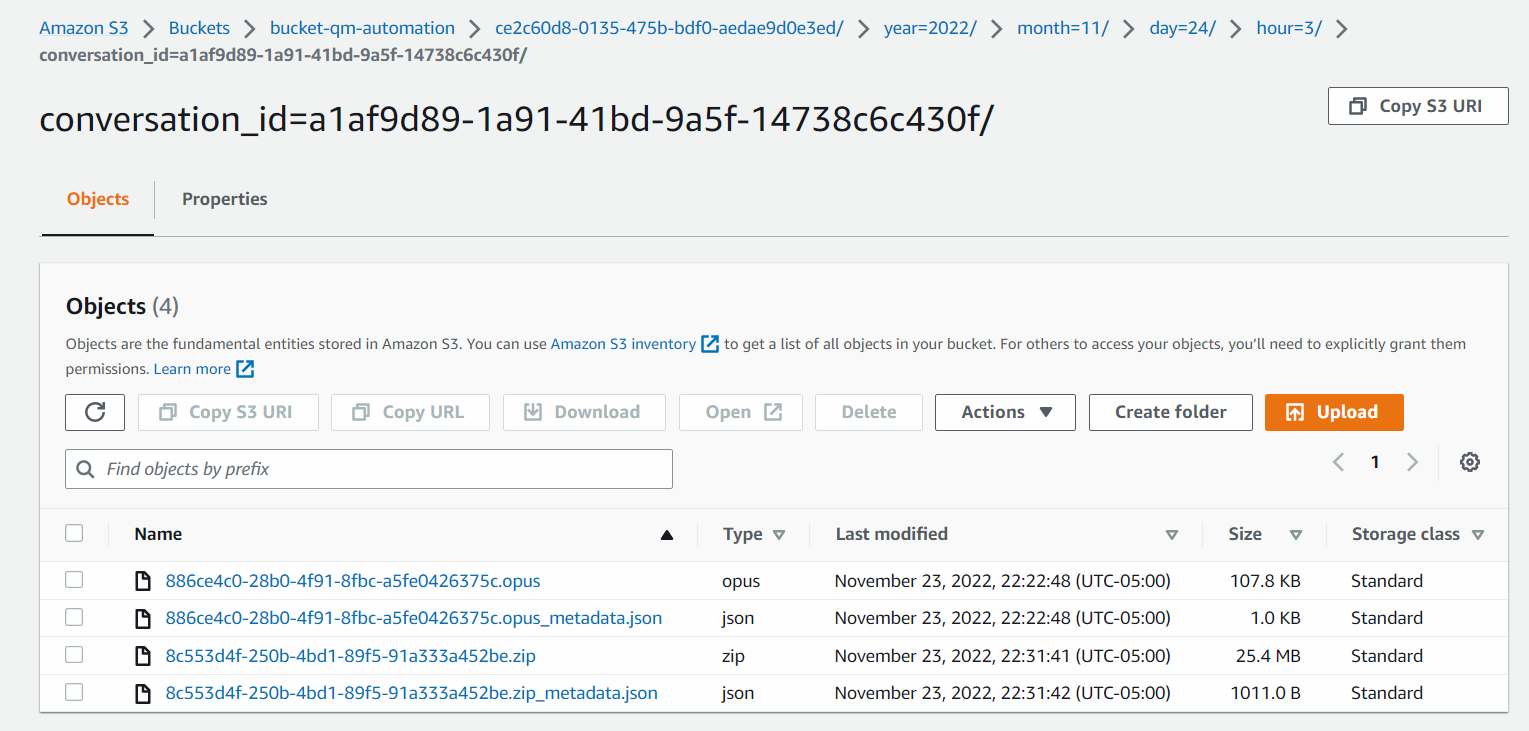
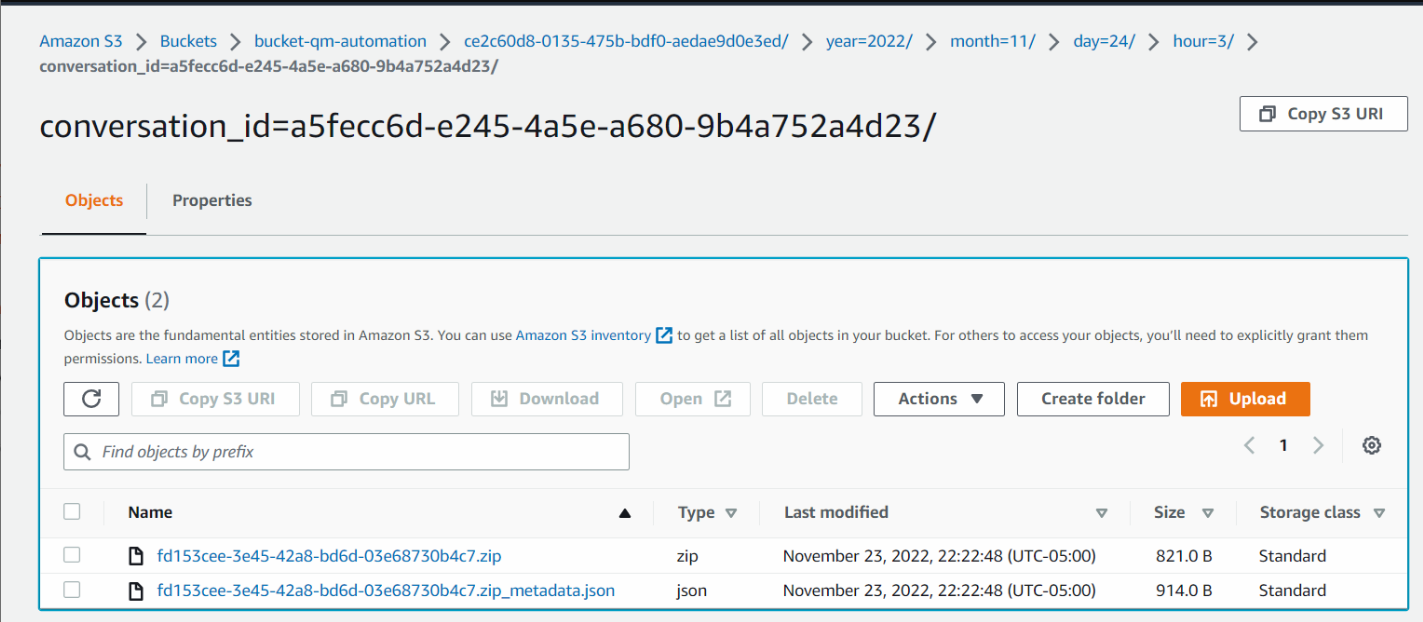
디지털 대화에는 다음과 같은 폴더 콘텐츠가 있을 수 있습니다.
아래 이미지에서 .zip 파일에는 디지털 녹음 파일이 포함되어 있으며 .json 파일은 해당 JSON 파일입니다.
이미지를 클릭하면 확대됩니다.
암호화
S3 버킷은 이미 AWS S3 서버 측 암호화(SSE)로 구성되어 있습니다. Amazon S3 관리형(SSE-S3) 암호화 키로 활성화되었거나 AWS 관리형 키로 활성화되었을 수 있습니다. 고객 제공 키 AWS 키 관리 서비스(SSE-KMS)에서.
AWS S3 서버 측 암호화(SSE)는 S3 버킷에 저장되어 있는 녹음 파일을 보호합니다. 파일이 버킷에서 검색되면 AWS는 파일 콘텐츠를 자동으로 해독합니다.
시스템에 추가로 활성화된 녹음 내보내기 암호화, S3 버킷에서 파일을 검색한 후 파일 콘텐츠를 직접 해독해야 합니다.